
Data scientists and artificial intelligence (AI) researchers require accuracy, simplicity, and speed for deep learning success. Faster training and iteration ultimately means faster innovation and faster time to market. Building a platform for deep learning goes well beyond selecting a server and GPUs. A commitment to implementing AI in your business involves carefully selecting and integrating complex software with hardware. NVIDIA® DGX A100 fast-tracks your initiative with a solution that works right out of the box, so you can gain insights in hours instead of weeks or months.
Today’s deep learning environments can cost hundreds of thousands of dollars in software engineering hours, and months of delays for the open source software to stabilize. With NVIDIA DGX A100 you’re immediately productive, with simplified workflows and collaboration across your team. Save time and money with a solution that’s up-to-date with the latest NVIDIA optimized software.
While many solutions offer GPU-accelerated performance, only NVIDIA DGX A100 unlocks the full potential of the latest NVIDIA® Tesla® V100, including next-generation NVIDIA NVLink™, and new Tensor Core architecture. DGX A100 delivers 3X faster training speed than other GPU-based systems by using the NVIDIA GPU Cloud Deep Learning Stack with optimized versions of today’s most popular frameworks.
High-performance training accelerates your productivity, which means faster time to insight and faster time to market.


Eliminate tedious set up and testing with ready-to-run, optimized AI software.

Experience simplified infrastructure design and capacity planning with one system for all AI workloads.

Increase data scientist productivity and eliminate non-value-added effort.
Up to 3X Higher Throughput for AI Training on Largest Models
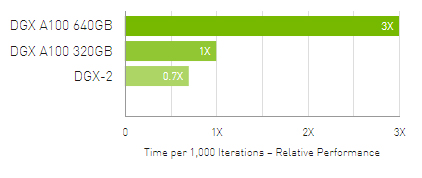
DLRM on HugeCTR framework, precision = FP16 | 1x DGX A100 640GB batch size = 48 | 2x DGX A100 320GB batch size = 32 | 1x DGX-2 (16x V100 32GB) batch size = 32. Speedups Normalized to Number of GPUs.
Up to 1.25X Higher Throughput for AI Inference
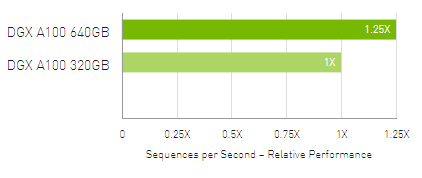
MLPerf 0.7 RNN-T measured with (1/7) MIG slices. Framework: TensorRT 7.2, dataset = LibriSpeech, precision = FP16.
Up to 83X Higher Throughput than CPU, 2X Higher Throughput than DGX A100 320GB
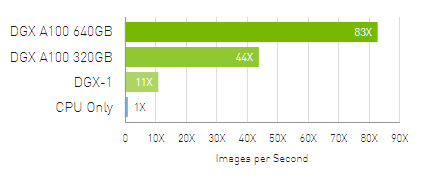
Big data analytics benchmark | 30 analytical retail queries, ETL, ML, NLP on 10TB dataset | CPU: 19x Intel Xeon Gold 6252 2.10 GHz, Hadoop | 16x DGX-1 (8x V100 32GB each), RAPIDS/Dask | 12x DGX A100 320GB and 6x DGX A100 640GB, RAPIDS/Dask/BlazingSQL. Speedups Normalized to Number of GPUs.
